All Categories
Featured
Table of Contents
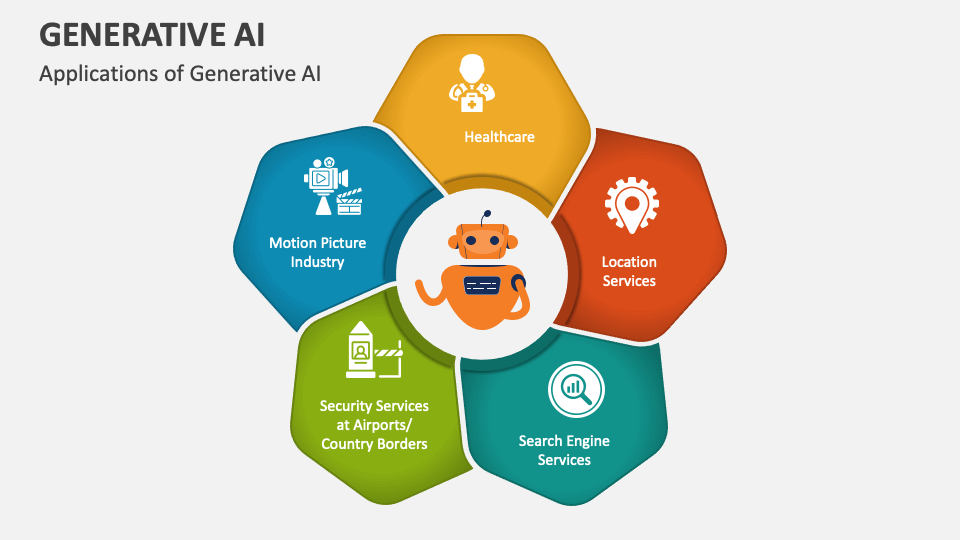
Generative AI has company applications past those covered by discriminative designs. Numerous algorithms and associated versions have been developed and educated to produce brand-new, sensible content from existing information.
A generative adversarial network or GAN is a machine discovering structure that places both neural networks generator and discriminator against each various other, therefore the "adversarial" part. The competition between them is a zero-sum game, where one agent's gain is an additional representative's loss. GANs were created by Jan Goodfellow and his coworkers at the College of Montreal in 2014.
Both a generator and a discriminator are frequently implemented as CNNs (Convolutional Neural Networks), specifically when functioning with pictures. The adversarial nature of GANs exists in a video game theoretic circumstance in which the generator network should compete against the enemy.
Explainable Ai
Its foe, the discriminator network, attempts to differentiate between examples attracted from the training data and those drawn from the generator - How does AI improve remote work productivity?. GANs will be considered successful when a generator develops a fake example that is so convincing that it can mislead a discriminator and human beings.
Repeat. Described in a 2017 Google paper, the transformer architecture is a maker learning framework that is highly effective for NLP all-natural language processing tasks. It learns to discover patterns in sequential data like written message or spoken language. Based on the context, the model can predict the following component of the collection, for instance, the following word in a sentence.
How Does Ai Enhance Customer Service?
A vector represents the semantic attributes of a word, with similar words having vectors that are enclose worth. For instance, the word crown could be stood for by the vector [ 3,103,35], while apple might be [6,7,17], and pear might look like [6.5,6,18] Naturally, these vectors are simply illustrative; the real ones have much more dimensions.
At this stage, details about the placement of each token within a series is added in the kind of another vector, which is summed up with an input embedding. The result is a vector mirroring the word's first definition and setting in the sentence. It's after that fed to the transformer semantic network, which includes 2 blocks.
Mathematically, the connections between words in an expression appear like ranges and angles in between vectors in a multidimensional vector room. This system has the ability to detect subtle ways also distant information aspects in a series impact and depend upon each various other. In the sentences I put water from the bottle into the cup until it was complete and I poured water from the pitcher into the cup till it was vacant, a self-attention device can differentiate the meaning of it: In the previous case, the pronoun refers to the mug, in the latter to the pitcher.
is utilized at the end to determine the likelihood of different outputs and select the most possible option. Then the created outcome is added to the input, and the entire process repeats itself. The diffusion design is a generative version that produces brand-new data, such as photos or audios, by imitating the information on which it was trained
Think about the diffusion version as an artist-restorer who researched paints by old masters and currently can repaint their canvases in the exact same style. The diffusion model does approximately the same thing in 3 main stages.gradually presents noise into the initial image until the outcome is merely a disorderly set of pixels.
If we return to our analogy of the artist-restorer, direct diffusion is handled by time, covering the painting with a network of fractures, dirt, and oil; occasionally, the painting is remodelled, including specific information and eliminating others. is like researching a paint to understand the old master's original intent. Can AI write content?. The design meticulously assesses just how the included noise modifies the data
How Do Ai And Machine Learning Differ?
This understanding allows the design to effectively reverse the procedure later. After discovering, this model can rebuild the altered information through the process called. It begins with a sound example and eliminates the blurs step by stepthe same means our artist obtains rid of contaminants and later paint layering.
Assume of latent representations as the DNA of a microorganism. DNA holds the core guidelines required to develop and preserve a living being. Unrealized depictions have the basic aspects of data, permitting the version to restore the initial details from this encoded significance. But if you alter the DNA molecule just a little bit, you obtain a completely various organism.
What Is The Connection Between Iot And Ai?
State, the girl in the 2nd leading right image looks a little bit like Beyonc yet, at the exact same time, we can see that it's not the pop vocalist. As the name suggests, generative AI transforms one type of photo into another. There is an array of image-to-image translation variants. This job involves extracting the style from a famous painting and applying it to one more photo.
The outcome of making use of Secure Diffusion on The results of all these programs are rather similar. Some users keep in mind that, on standard, Midjourney draws a bit more expressively, and Secure Diffusion complies with the request much more plainly at default settings. Scientists have actually additionally utilized GANs to create synthesized speech from message input.
Ai Industry Trends

The major job is to carry out audio analysis and develop "vibrant" soundtracks that can transform relying on just how individuals connect with them. That stated, the music may change according to the environment of the video game scene or depending on the intensity of the customer's workout in the health club. Read our post on find out more.
Practically, videos can likewise be generated and transformed in much the exact same means as photos. While 2023 was marked by advancements in LLMs and a boom in image generation modern technologies, 2024 has seen substantial improvements in video clip generation. At the beginning of 2024, OpenAI introduced an actually outstanding text-to-video version called Sora. Sora is a diffusion-based model that generates video clip from fixed noise.
NVIDIA's Interactive AI Rendered Virtual WorldSuch synthetically developed information can aid create self-driving autos as they can utilize generated online world training datasets for pedestrian discovery, for instance. Whatever the technology, it can be used for both excellent and poor. Obviously, generative AI is no exemption. Presently, a pair of challenges exist.
Because generative AI can self-learn, its habits is challenging to control. The results given can typically be much from what you anticipate.
That's why many are implementing dynamic and smart conversational AI designs that customers can communicate with via text or speech. GenAI powers chatbots by comprehending and producing human-like text reactions. Along with customer care, AI chatbots can supplement marketing efforts and support interior communications. They can additionally be incorporated into web sites, messaging apps, or voice aides.
Ai Trend Predictions
That's why a lot of are applying dynamic and intelligent conversational AI designs that consumers can communicate with via text or speech. GenAI powers chatbots by recognizing and producing human-like message reactions. Along with customer service, AI chatbots can supplement marketing initiatives and assistance inner communications. They can likewise be integrated right into sites, messaging apps, or voice assistants.
{kind=link}
Table of Contents
Latest Posts
What Is Ai-generated Content?
Speech-to-text Ai
Ai In Healthcare
More
Latest Posts
What Is Ai-generated Content?
Speech-to-text Ai
Ai In Healthcare